Pick the thing that slows your team down most:
- The staging queue. Someone is testing a migration; your PR waits.
- "Works on my Compose." OAuth callbacks, CORS, security groups, cert expiry — none of it shows up locally, all of it shows up in prod.
- The forgotten RDS instance running up $900/month because nobody remembered who spun it up.
- The PR reviewed as a green checkmark and a diff, because nobody had anywhere to actually click it.
All of these share a shape. Your branch doesn't have its own cloud. Production has one. Staging has one, sort of. Everything else lives in a spreadsheet of ad-hoc environments and hope.
Why we built capsules
Preview environments aren't a new idea. Vercel and Netlify did it for frontends. A handful of Kubernetes-based tools do it for teams with a platform engineer and a patient quarter. Nobody had done it for a full-stack cloud application — the actual kind, with managed Postgres, a queue, a hosted auth provider, and five services talking over real networks — without a fixed cluster, hand-authored manifests, and a meaningful week of setup.
We built capsules because we wanted every branch to have that environment by default, with zero config, on the cloud you already use.
And if you've ever handed a ticket to a coding agent, you know the other half of this. The agent writes the code, the agent pushes, the agent then has nowhere to check its work. Compose lies. Shared staging is someone else's. The agent ships its best guess. We felt that one too.
What a capsule is
A capsule is a full production-shaped environment, provisioned per git branch, on your cloud, with a unique HTTPS URL.
Not a namespace. Not a container. A real deployment, wired end-to-end: VMs, databases, caches, queues, managed services, secrets, DNS, TLS. The same shape as production, on the same cloud, built from the same source.
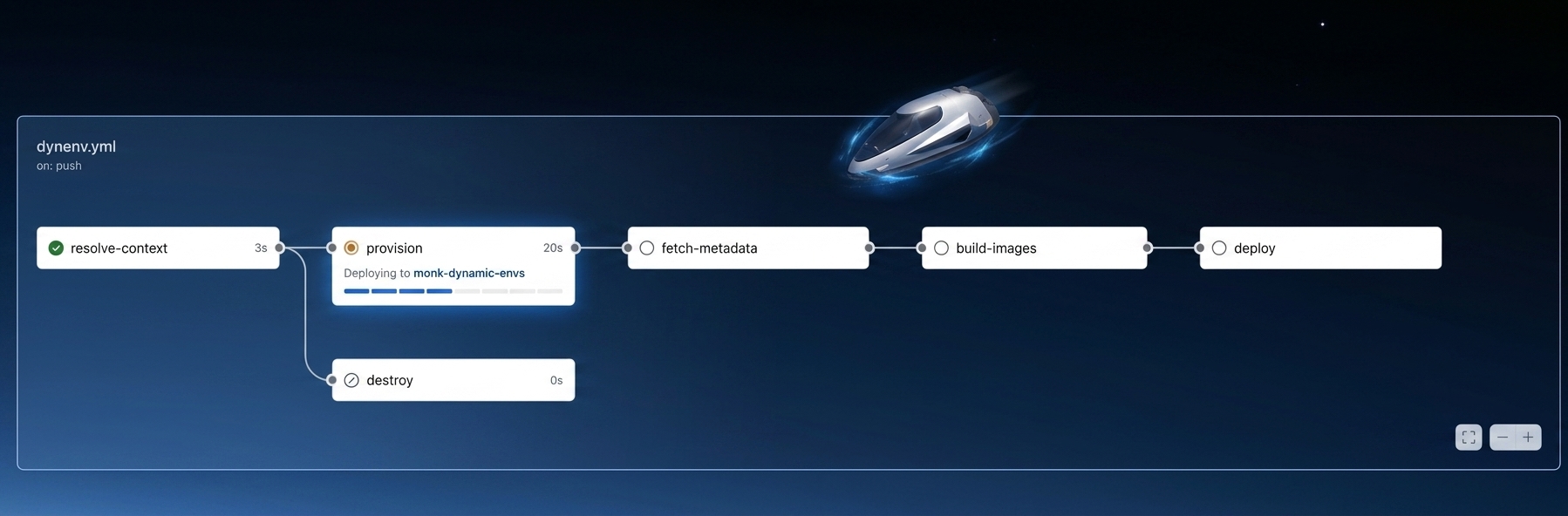
It works like this:
- Open your project in your IDE — Monk works best with monorepos today. Monk reads your code — framework, services, dependencies, data stores, integrations — and writes a manifest you check in.
- Say
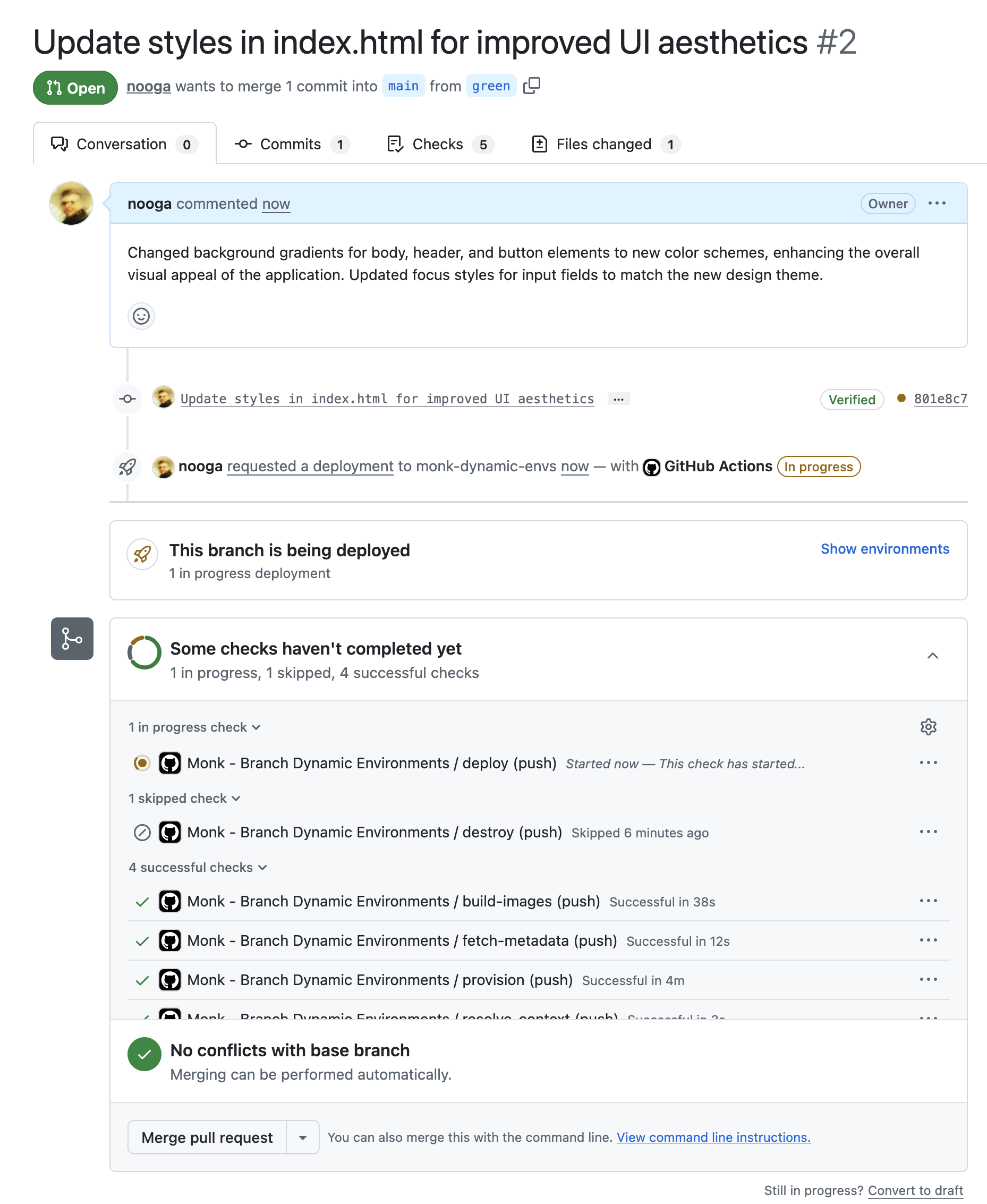
set up Capsulesin the Monk chat. Pick a cloud and a region. Monk generates the GitHub workflow and commits it. - Push a branch. A few minutes later, a preview URL shows up on the PR.
- Merge or delete the branch. The capsule tears itself down. Nothing lingers.
No per-branch manifests. No cluster to pre-provision. No ticket.
What changes the day you turn them on
- PRs are clickable. Reviewers open the URL. Product looks at the feature. QA hits real endpoints. The PR's proof is a working link, not a green checkmark.
- "Works in staging, breaks in prod" goes away. Staging for this branch is shaped like prod — same managed services, same networks, same TLS. The class of bugs that only shows up when real things talk to each other now shows up in the dev loop.
- Ten branches, ten productions, zero coordination. No queueing. No conflicts. Parallel work is actually parallel.
- Coding agents can verify their own work. An agent that pushes to a branch can then hit the deployed app, call APIs, read logs, check the state of every service, fix what it got wrong, and push again. The PR it hands off is tested, not guessed.
- Infra changes become PRs. Want to swap the cache engine, try a smaller VM, benchmark a different database? Change the manifest. The capsule rebuilds. Merge when the preview works. More on this in The other half of the harness.
Why this works on day one
Capsules aren't a thin wrapper over terraform apply. The engineering underneath is the reason they work out of the box instead of after a platform team's quarter.
Three things have to be true at once:
- Typed, lifecycle-aware primitives for every cloud resource. Monk ships a library of them — each one knows how to provision, configure, connect, and tear itself down. The graph for your app builds itself by reading your code against this library. Nothing is hand-authored.
- A persistent orchestrator with state. Capsules have to remember what they created so they can clean it up, and the orchestrator has to reason about drift and lifecycle over time. Monk runs that state — not a shell script, not an LLM conversation.
- Scoped credentials. A branch never holds your full production secret bundle. Credentials are per capsule, per entity, per API surface. Short-lived tokens get minted at runtime.
This is also the reason capsules run on AWS, Azure, GCP, and DigitalOcean on the same day. The orchestrator is the portability, not a YAML abstraction over it.
Practical details worth knowing
- Cost control is built in. Capsules hibernate on a schedule you set — weekdays only, off overnight, whatever fits. Override per capsule when a demo runs late.
- Status shows up on the PR. Each capsule registers as a GitHub Deployment, so reviewers see live / deploying / failed without leaving GitHub.
- Secrets are GitHub-native. Cloud credentials and app secrets live in GitHub's encrypted environment secrets.
Setting a schedule is one prompt:
It doesn't touch your existing setup
Capsules are additive. Your current production keeps running however it runs today — on whatever cloud, through whatever pipeline, with whatever secrets. Capsules don't redeploy it, don't rewrite its config, and don't share credentials with it.
Each capsule runs on its own ephemeral cluster, scoped to an account and region you pick up front, with credentials minted fresh per capsule. Branches you want left alone — main, release branches, anything matching a pattern — are excluded by filter. When the branch goes away, the capsule is gone. Nothing lingers.
Turn capsules off tomorrow and production is exactly where you left it.
Turn them on
If you already have a Monk-deployed project, open the chat and say:
If you don't, open your project in your IDE, deploy your main branch once, then use the prompt above.
Push a branch. Wait a few minutes. Click the URL.
That's the workflow. Everything after it is git.
More in the Capsules docs.

